
How to Build Lightweight Data Pipeline and MLOps Server in On-premises Environment
Streamlined Airflow & MLflow Operations, Enhanced by PostgreSQL. Leverage Feast’s Online Feature Store with Redis, and Tap into Kafka. Monitor with NannyML and Process data with Polars.

🌟 From Data Science to MLOps: Navigating the On-Premises Frontier
As the sun sets on my days as a data scientist, I find myself standing at the crossroads of transformation. The journey from feature engineering to model deployment has led me to a new horizon: MLOps. In this article, I’ll unravel the intricacies of building a lightweight data pipeline and MLOps server within the confines of an on-premises environment. Buckle up—we’re about to embark on a voyage where code meets infrastructure, and insights collide with reality. 🚀🔍
P.S: I was motivated to share this post because I have experienced the transition from a Data Science (DS) to a Machine Learning (ML) role, which required hands-on MLOps work in an on-premises environment.
Ready to embark on this transformative journey? Let’s dive in! 🌟

Unlock the Power of On-Premises AI/ML Deployment with Our Cutting-Edge Template
Embark on a journey of seamless data management and model deployment with our meticulously crafted template, tailored for organizations that demand efficiency and precision. This solution is the perfect fit for handling lightweight batch data processing, streaming data, and deploying a select suite of models in an on-premises setting.
At the heart of our environment lies a robust trio: Airflow, MLFlow, and Feast, each anchored by a PostgreSQL database, ensuring unparalleled data integrity. Our online feature store taps into the speed of Redis, while the Feast push server and Apache Kafka support cater to your streaming ingestion needs. This infrastructure is not just about managing workflows; it’s about empowering your data pipeline and elevating model tracking to new heights.
For those who venture into the realm of big data, our template is designed to grow with you. Integrate powerhouse technologies like Kubernetes, Kubeflow, Hadoop, Hive, and Apache Spark to unlock distributed computing capabilities that will scale your data processing to meet the demands of the big data challenge.
Below diagram depicts the overall view of our MLOps environment:
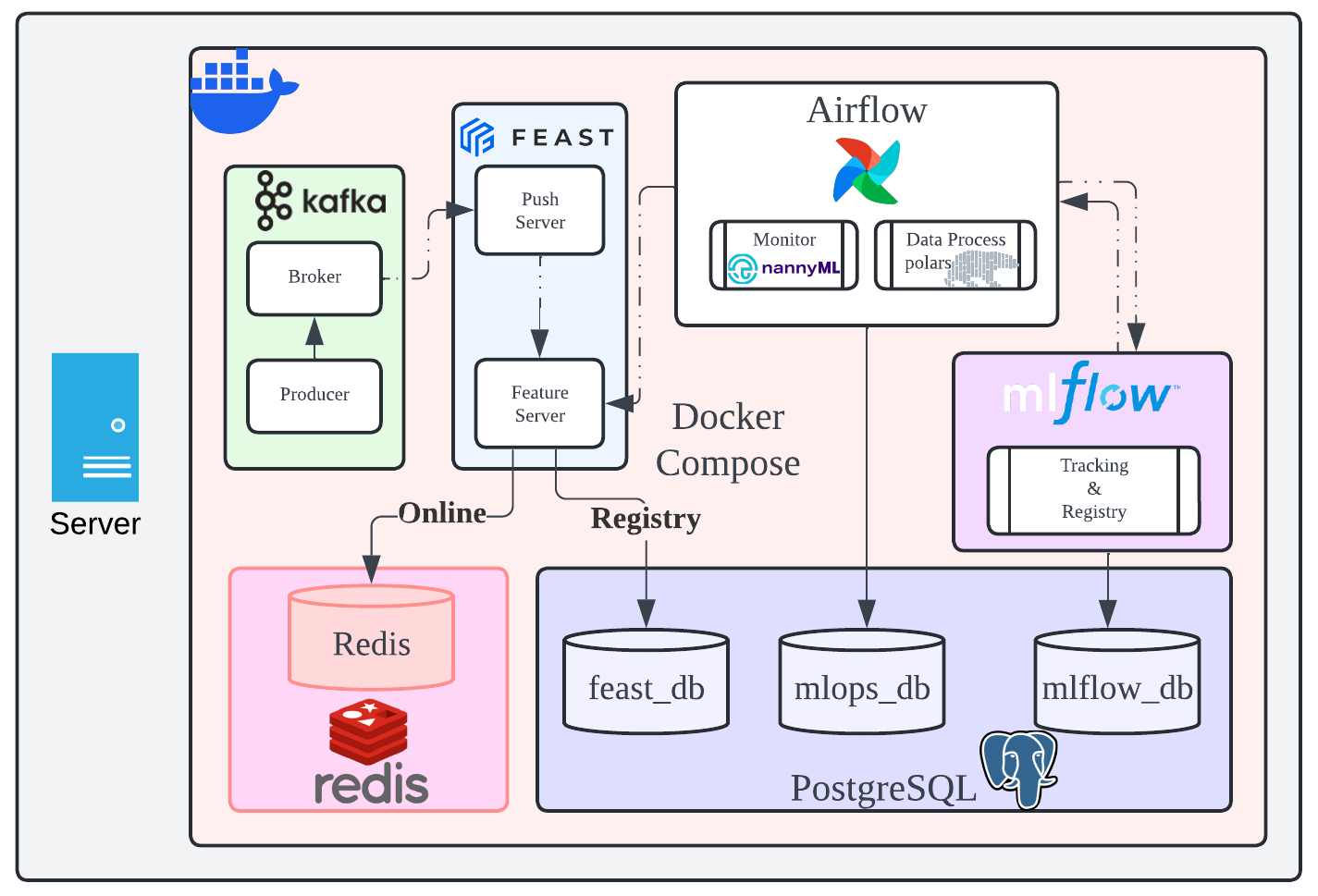
Building a Robust MLOps Environment with Docker Compose
Embark on the creation of a state-of-the-art MLOps system that is both versatile and robust. Our journey begins with our Docker Compose file, which outlines a suite of services designed to streamline your data operations.
Database Service: The Foundation
Our system kicks off with a PostgreSQL database service, constructed from a custom Dockerfile within the ./docker/postgres directory. It’s configured to restart automatically and logs are managed to ensure optimal performance. The service is exposed on port 32769 and includes volume mappings for persistent data storage and initialization scripts. Crucial environment variables define the user, password, and multiple databases (mlops_db, mlflow_db, feast_db) to cater to our diverse data needs. A health check ensures the database is ready to handle queries before other services start.
######################################################
# DATABASE SERVICE
######################################################
postgres:
build: './docker/postgres'
restart: always
container_name: postgres
logging:
driver: "json-file"
options:
max-file: "5"
max-size: "10m"
ports:
- "32769:5432"
volumes:
- ./mnt/postgres/pgdata:/var/lib/postgresql/data/pgdata
- ./docker/postgres/entrypoint_initdb:/docker-entrypoint-initdb.d
environment:
- POSTGRES_USER=mlops
- POSTGRES_PASSWORD=mlops
- POSTGRES_MULTIPLE_DATABASES=mlops_db, mlflow_db, feast_db
- PGDATA=/var/lib/postgresql/data/pgdata
healthcheck:
test: [ "CMD", "pg_isready", "-q", "-d", "mlops_db", "-U", "mlops" ]
timeout: 45s
interval: 10s
retries: 10POSTGRES_MULTIPLE_DATABASES: This is the name of the environment variable. It’s not a standard PostgreSQL environment variable. The command of multiple database creation in docker-compose enables robust handling of databse management. By mounting entrypoint_initdb.sh to /docker-entrypoint-initdb.d, automatically run the script when the container launchs and create the databases according to this environment variable.
Adminer: Database Management Made Simple
Adminer, a lightweight database management tool, is set up to connect to our PostgreSQL service. It provides a web interface accessible on port 32767 for easy database operations.
adminer:
image: wodby/adminer:latest
restart: always
container_name: adminer
logging:
driver: "json-file"
options:
max-file: "5"
max-size: "10m"
ports:
- "32767:9000"
environment:
- ADMINER_DEFAULT_DB_DRIVER=psql
- ADMINER_DEFAULT_DB_HOST=postgres
- ADMINER_DEFAULT_DB_NAME=mlops_db
healthcheck:
test: [ "CMD", "nc", "-z", "adminer", "9000" ]
timeout: 45s
interval: 10s
retries: 10Open browser and enter http://localhost:32767 to launch UI as you need.
Airflow: Orchestrating Data Workflows
The Airflow service, built from ./docker/airflow, orchestrates our data pipelines. It depends on the health of the PostgreSQL service and mounts several volumes for configuration, DAGs, logs, plugins, and projects. Airflow’s webserver is available on port 8080, and a health check ensures it’s ready to manage our workflows.
######################################################
# AIRFLOW
######################################################
airflow:
build: ./docker/airflow
restart: always
container_name: airflow
depends_on:
postgres:
condition: service_healthy
volumes:
- ./mnt/airflow/airflow.cfg:/opt/airflow/airflow.cfg
- ./mnt/airflow/dags:/opt/airflow/dags
- ./mnt/airflow/logs:/opt/airflow/logs
- ./mnt/airflow/plugins:/opt/airflow/plugins
- ./mnt/airflow/feast:/opt/airflow/projects
ports:
- 8080:8080
healthcheck:
test: [ "CMD", "nc", "-z", "airflow", "8080" ]
timeout: 45s
interval: 10s
retries: 10The structure would look like:
airflow
│ airflow.cfg
│
├───dags
│ README.md
│ sample_feast_dag.py
│ sample_mlflow_dag.py
│ sample_postgres_dag.py
│
├───files
│
├───nannyml
│
├───scripts
│
├───sql
│ birth_date.sql
│ pet_schema.sql
│ populate_pet_table.sql
│
├───feast
│
├───logs
│
└───pluginsThe key to harnessing the full potential of Airflow lies in understanding its directory structure—a well-organized framework that ensures every piece of your data pipeline is exactly where it needs to be. Let’s dive into the anatomy of an Airflow setup:
Root Directory: The Command Center At the heart of it all is the
airflowdirectory, your command center. Here, you’ll find theairflow.cfgfile, the mastermind configuration that dictates how your Airflow environment behaves.DAGs Folder: The Blueprint Collection Within the
dagsfolder, creativity meets execution. It’s home to your DAGs (Directed Acyclic Graphs), the blueprints of your data workflows. This folder includes:sample_feast_dag.py: A sample DAG demonstrating Feast integration.sample_mlflow_dag.py: An example DAG for MLflow operations. This is sklearn with catboost and iris dataset.sample_postgres_dag.py: A template DAG for PostgreSQL tasks.
Files Folder: The Resource Library The
filesdirectory stands ready to store any additional resources your DAGs might need, acting as a centralized intemediate data or file resource.NannyML Folder: This folder intended to store any NannyML outputs/plot, monitoring the performance and health of ML models.
Scripts Folder: The
scriptsdirectory is your directory for saving any codes for your work.SQL Folder: The Query Vault The
sqlfolder is the query vault for airflow DAGs, containing SQL scripts such as:birth_date.sql: A script to handle birth date to query the database.pet_schema.sql: The schema definition for a pet database.populate_pet_table.sql: A script to populate the pet table with data.
Feast Folder: The Feature Feast The
feastdirectory is where you’ll save Feast work from airflow, an essential feature store for your ML models, ensuring they’re always fed with the freshest data.Logs Folder: The Chronicle The
logsfolder is the chronicle of your Airflow journey, capturing every step, every task, and every run, providing you with a comprehensive history of your operations.Plugins Folder: The Customization Corner Last but not least, the
pluginsdirectory is the customization corner, allowing you to extend Airflow’s capabilities with custom plugins tailored to your needs.
This structured approach not only brings order to potential chaos but also empowers you to build, manage, and monitor your data workflows with unparalleled efficiency. Embrace the structure, and let Airflow propel your data operations to new heights.
MLflow: Tracking Experiments with Ease
MLflow is our experiment tracking tool, built from ./docker/mlflow. It stores data in a dedicated volume and offers its UI on port 5000. Like Airflow, it waits for PostgreSQL to be healthy before starting.
######################################################
# MLFLOW
######################################################
mlflow:
build: ./docker/mlflow
restart: always
container_name: mlflow
depends_on:
postgres:
condition: service_healthy
volumes:
- ./mnt/mlflow:/mlflow
ports:
- 5000:5000The Setup: With a swift update to the package list and installation of essential build dependencies, we pave the way for MLflow and its PostgreSQL companion, psycopg2. This ensures seamless interaction with the PostgreSQL database, setting the stage for robust data tracking.
# Base Image
FROM python:3.8-slim-buster
WORKDIR /mlflow
RUN apt-get update && \
apt-get -y install libpq-dev gcc && \
pip install mlflow psycopg2
ENV BACKEND_URI postgresql+psycopg2://mlops:mlops@postgres:5432/mlflow_db
EXPOSE 5000
CMD mlflow server --backend-store-uri $BACKEND_URI --host 0.0.0.0 --port 5000We leave --default-artifact-root option as default for saving MLflow artifact in container mount folder for data persistence.
Feast: Feature Store for Machine Learning
Our feature store is powered by Feast and Redis. Redis, running on redis:7.2-alpine, provides a fast in-memory NoSQL data store, while Feast serves the online feature store and push server, facilitating streaming ingestion with links to Redis. Both services have health checks to ensure reliability.
######################################################
# FEAST
######################################################
redis:
image: redis:7.2-alpine
restart: always
volumes:
- ./mnt/redis:/data
ports:
- "6379:6379"
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 10s
timeout: 30s
retries: 50
start_period: 30s
feature_server:
container_name: feast_feature_server
build: ./docker/feast
restart: always
depends_on:
postgres:
condition: service_healthy
ports:
- "6566:6566"
links:
- redis
healthcheck:
test: "${DOCKER_HEALTHCHECK_TEST:-curl localhost:6566/health}"
interval: "5s"
retries: 5
push_server:
container_name: feast_push_server
build: ./docker/feast
restart: always
depends_on:
feature_server:
condition: service_healthy
postgres:
condition: service_healthy
ports:
- "6567:6566"
links:
- redisThe push server you’ve deployed using Docker Compose on port 6567 offers several benefits, particularly in the context of feature management in machine learning operations (MLOps). Here’s why it’s beneficial:
Independent Scaling: By separating the write operations (pushing features) from the read operations (serving features), you can scale each part independently based on their specific load and performance requirements. For instance, if you have a high frequency of feature updates but relatively stable read patterns, you can allocate more resources to the push server without over-provisioning the serving component.
Resource Isolation: This separation also means that intensive write operations won’t interfere with the performance of read operations. It ensures that the feature serving remains fast and responsive, even when there’s a heavy load on the push server.
Simplified Architecture: Pushing features through an HTTP request to the push server simplifies the architecture.
Flexibility in Feature Management: The ability to push features through an HTTP request provides flexibility. You can easily integrate this process with different parts of your MLOps pipeline or even trigger pushes programmatically from various services or applications.
Enhanced Security: Having a dedicated push server allows you to implement security measures specifically for write operations, such as authentication and authorization, without complicating the read-side security.
We can request push to online store like below in modeule with Python.
requests.post("http://push_server:6567/push", data=json.dumps(push_data))Kafka: Real-Time Data Streaming
The Kafka ecosystem includes Zookeeper and a Broker, ensuring a robust messaging system for real-time data streaming. The broker service exposes ports 9092 and 29092 for internal and external communication, respectively.
######################################################
# KAFKA
######################################################
zookeeper:
image: confluentinc/cp-zookeeper:7.0.1
container_name: zookeeper
restart: always
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-kafka:7.0.1
container_name: broker
restart: always
ports:
- "9092:9092"
- "29092:29092"
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_INTERNAL:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092,PLAINTEXT_INTERNAL://broker:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
kafka_events:
build: ./docker/kafka
restart: always
depends_on:
- broker
container_name: kafka_eventsKafka Events: Custom Event Handling
A custom Kafka Events service is built to handle specific event processing needs, completing our MLOps system setup.
kafka_events:
build: ./docker/kafka
restart: always
depends_on:
- broker
container_name: kafka_eventsThe dockerfile will invoke Kafka producer to fetch parquet data to stream online.
FROM python:3.8-slim
# Copy app handler code
COPY ./kafka_sample.py kafka_sample.py
COPY ./driver_stats.parquet .
# Install dependencies
RUN pip3 install kafka-python==2.0.2
RUN pip3 install pandas
RUN pip3 install pyarrow
CMD [ "python", "-u", "kafka_sample.py", "--mode", "setup", "--bootstrap_servers", "broker:29092"]In conclusion
by leveraging Docker Compose, we’ve created an MLOps environment that is not only comprehensive but also modular and versatile. Each service is meticulously configured to work in harmony, providing a seamless experience for managing lightweight data pipelines and deploying AI/ML models.
Summary of Work
Functionality:
Streamlined Workflow Management: The use of Airflow allows for the orchestration of complex data workflows, automating and simplifying the process of managing data pipelines.
Experiment Tracking: MLflow provides a platform for tracking experiments, managing the ML lifecycle, and storing artifacts, making it easier to reproduce results and iterate on models.
Feature Store Integration: Feast serves as an online feature store, interfacing with Redis for quick data retrieval, which is essential for real-time machine learning applications.
Real-Time Data Streaming: The inclusion of Apache Kafka enables the handling of high-throughput, real-time data streams, which is crucial for timely insights and decision-making.
Database Service: A robust PostgreSQL backend ensures data integrity and provides a solid foundation for all data-related operations within the MLOps environment.
Benefits:
Efficiency: Automating data pipeline and model deployment processes reduces manual effort and increases productivity.
Reliability: Health checks and automatic restarts ensure that each service is always running optimally, providing a reliable infrastructure.
Flexibility: The modular nature of Docker Compose allows for easy updates and customization of the MLOps environment to fit specific requirements.
Reproducibility: With detailed tracking and version control, experiments and models can be easily replicated, facilitating collaboration and knowledge sharing.
Future Work: Elevating Scalability to New Heights
As we look to the horizon, our MLOps system stands poised for a transformative leap in scalability. The foundational architecture is meticulously designed to embrace expansion, accommodating the burgeoning demands of big data processing. Here’s what the future holds:
Kubernetes Integration: We will harness the power of Kubernetes to orchestrate containerized applications across a cluster of machines, ensuring seamless scalability and management. This will enable our system to dynamically adjust resources, handle increased loads, and maintain high availability with minimal downtime.
Hadoop Ecosystem: By incorporating Hadoop and its suite of tools like Hive and Spark, we will unlock distributed computing capabilities. This will allow us to process vast datasets efficiently, store data reliably in HDFS, and perform complex analytics at scale.
Advanced Monitoring Solutions: To keep pace with the expanded infrastructure, we will implement sophisticated monitoring solutions. These will provide deeper insights into system performance, resource utilization, and operational health, ensuring that as we grow, we maintain the highest standards of reliability and performance using the tool such as Grafana.
Cloud Integration: We are committed to continuous innovation. Our roadmap includes exploring cutting-edge technologies and methodologies that can further enhance our system’s scalability to cloud.
Community Collaboration: Recognizing the power of collective wisdom, we will foster a community of users and contributors. Their feedback and contributions will be invaluable in refining our scalability solutions, ensuring that our system not only meets but exceeds the expectations of the data science and machine learning communities.
The journey ahead is filled with exciting possibilities. As we expand our MLOps system, we remain dedicated to providing a robust, scalable solution that empowers organizations to harness the full potential of their data.
Additional Notes
For those who seeks to understand whole picture with detailed process and definition and architecture of MLOps, it is recommended to reference great paper below.
[1] Dominik Kreuzberger, Niklas Kühl, and Sebastian Hirschl. 2023. Machine learning operations (mlops): Overview, definition, and architecture. IEEE Access (2023).
References & Links
Work cited: feast-dev/feast-workshop: A workshop with several modules to help learn Feast, an open-source feature store https://github.com/feast-dev/feast-workshop (github.com)
Github repo: takehiro177/mlops-onpremises-slim (github.com)
Linkedin profile: www.linkedin.com/in/takehiro-ohashi-b54101174