

Understand The LLM Twin and Why Important

An LLM twin is an AI character that mimics your writing style, voice, and personality using a large language model (LLM). Unlike generic LLMs trained on vast internet data, an LLM twin is fine-tuned specifically on your data, reflecting your unique traits.
Key Points:
Personalized AI: The LLM twin is a digital version of you, trained on your writing to capture your style and voice.
Style Transfer: Similar to how AI can generate images in the style of famous artists, an LLM twin can write like you by learning from your data.
Advanced Techniques: Uses Retrieval-Augmented Generation (RAG) to enhance the model with your accumulated work and knowledge.
Applications:
Social Media: Tailor the LLM to write LinkedIn posts and X threads.
Personal Messages: Adapt the LLM to reflect your informal communication with friends and family.
Academic Writing: Fine-tune the LLM for formal and educational content.
Coding: Train the LLM to write code in your style.
This approach ensures the AI captures the essence of your persona, making it a powerful tool for personalized content creation. In this work, you will learn how to create LLM twin which writes personalized technical blog and save a lot of time. Now engineers can focus more on complex tasks and learning important skills!
Understand The Challenge and Contribution of This Work
Developing end-to-end infrastructure and environment for managing LLM is complex and required a lot of time and effort. In this work, you will learn how to deploy end-to-end LLM data pipeline including how to process and LLMOps capability that is ever earsier by leveraging Cohere and Databricks.
You will learn:
collect data as streaming data source from code and pdf documents.
serve Cohere LLM on Databricks Mosaic AI.
process texts using LangChain with Cohere LLM on model serving endpoint and create vector search using Cohere Embed.
finetune Cohere through API and deploy finetuned model.
Advanced LangChain method such as Ensemble Retriever on Databricks vector search.
Deploy agent application to host LLM twin
Before start you will need Unity Catalog enabled workspace on Databricks and Cohere account.
Collecting Data as Streaming Datasource
To collect your github repository data and ingest them as streaming datasource, you will clone all your repositories accouring to its updating time. Earch time the job is runed the github crawl newly update or added repository and retrieve all file as text and save to json format in DBFS (see: src/data_ingestion/git_crawler.py).
The newly added json files are appended to delta table by Auto Loader. Other resources such as pdf files are uploaded into object storage and ingested similary.
query = (spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("multiline", "true")
.option("cloudFiles.schemaLocation", "dbfs:/twinllm/checkpoint/bronze/gitrepos")
.option("cloudFiles.inferColumnTypes", "True")
.load(input_path)
.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "dbfs:/twinllm/checkpoint/bronze/gitrepos")
.trigger(availableNow=True)
.table("portfolio.twinllm.bronze_gitrepo_table")
)
query.awaitTermination()Serving Cohere LLM on Mosaic AI
To serve Cohere model on Mosaic AI, register your Cohere API key on databricks secrets and run below code, and you will see your cohere model on Serving tab located in databricks UI.
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
client.create_endpoint(
name="cohere-embed-endpoint",
config={
"served_entities": [
{
"name": "test",
"external_model": {
"name": "embed-english-v3.0",
"provider": "cohere",
"task": "llm/v1/embeddings",
"cohere_config": {
"cohere_api_key": "{{secrets/scope/key}}",
}
}
}
]
}
)This endpoint can be called by mlflow.deployments.get_deploy_client("databricks") as client and is used for preprocessing texts to create embedding vector. Futhermore, if you change the value on key “name“ to your Cohere finetuned model id, you can call finetuned Cohere Chat models.
Processing Texts Using LangChain with Cohere LLM on Databricks and Create Vector Search Using Cohere Embed
For long texts data such pdf documents, it is required to split as chunks and further retrieve them from vector database. However, splitting texts in domain-specific documents without proper processing may break information and fail to be retrieved by RAG. Leveraging Langchain SemanticChunker to split texts according to semantic meaning enhances quality of vector database.
from langchain_cohere import CohereEmbeddings
from langchain_experimental.text_splitter import SemanticChunker
cohere_embeddings = CohereEmbeddings(model="embed-english-light-v3.0")
text_splitter = SemanticChunker(cohere_embeddings, breakpoint_threshold_type="gradient")
new_chunks = text_splitter.split_text(text)Similary, code files in github may required to be summarized and distill information. This is achieved by Cohere chat to summarize the content in code and extract meaningful code snippest explanation as text (see: ser/data_processing/silver/silver_gitrepo_table.py).
Finally, you will need to create text_vector column by using Cohere Embed to creat embedding vector, and this column is used to index on gold table and using create delta sync index with self managed embedding by the following.
vsc.create_delta_sync_index(
endpoint_name=VECTOR_SEARCH_ENDPOINT_NAME,
index_name=vs_index_fullname,
source_table_name=source_table_fullname,
pipeline_type="TRIGGERED",
primary_key="gitrepo_file_id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)You will see the end-to-end data pipeline to create vector search is looks like the following on your workflows. The job can be runed as schedule you define and new data is ingested periodically and added to vector database to be used in subsequent RAG process.

Finetune Cohere Model Through API and Deploy on Serving Endpoint
In this section, you will need to create finetune training data with jsonl format for Cohere API to create as database and use it to finetune on the Cohere Dashboard.
To create this dataset, you need to create query content column. This column contains the prompt text input for Cohere model. The example is shown in below where “TOPIC“ is the topic you want to LLM to write about, and this topic is used to search similar texts in vector search as RAG. The retrieved texts is then added to subsequent part in the question.
def add_topic_to_query(topic):
question = """Write technical blog that demonstrates knowledge and best practice for "TOPIC" and its technical advantage and describes code snippest from the piece of information in the text bellow: """
question = question.replace("TOPIC", topic)
return questionRemember that Cohere finetune accept each conversation turn is within 8192 tokens for finetune dataset. I recommend by calculating token size for the final question as an input prompt.
Afther that, simply prepare the historical blog writing text and create text column that you want to Cohere to generate. This text is your own historical post such as own posts in Substack. Finally, you run following code to create datasets using jsonl file you created from two columns (see: src/model_serving/train_model_cohere.py) and call API to start finetune process on Cohere platform.
import cohere
# instantiate the Cohere client
co = cohere.Client(api_key)
# create cohere finetune tarining dataset through api
chat_dataset = co.datasets.create(name="twinllm-dataset",
data=open("/Workspace/Users/YOUR_USER/TwinLLM/src/data/cohere_finetune_data.jsonl", "rb"),
type="chat-finetune-input")
from cohere.finetuning import (
BaseModel,
FinetunedModel,
Hyperparameters,
Settings,
WandbConfig
)
hp = Hyperparameters(
early_stopping_patience=3,
early_stopping_threshold=0.001,
train_batch_size=2,
train_epochs=10,
learning_rate=0.01,
)
finetuned_model = co.finetuning.create_finetuned_model(
request=FinetunedModel(
name="cohere-twinllm-finetuned-model",
settings=Settings(
base_model=BaseModel(
base_type="BASE_TYPE_CHAT",
),
dataset_id="twinllm-dataset-nt2013",
hyperparameters=hp,
),
)
)Go to Cohere Dachboard and see the result. The accuracy is provided as comparison of with and withought finetuning generation. Without GPUs and cost on computing, you will get finetune model and run experiment on just click and run at low cost with enterprise level quality LLM!

LangChain Ensemble Retriever on Databricks Vector Search.
As there can be multiple documents resources, combining retrieval from multiple resources is essential to produce high quality RAG. LangChain has EnsembleRetriever which can also works for multiple vector search index on Databticks. Below code combines RAG from github repository and pdf datasource.
from langchain.retrievers import EnsembleRetriever
from langchain_databricks.vectorstores import DatabricksVectorSearch
from langchain_cohere import CohereEmbeddings
embeddings = CohereEmbeddings(
model="embed-english-v3.0",
)
gitrepo_vector_search = DatabricksVectorSearch(
endpoint=model_config.get("vector_search_endpoint_name"),
index_name=model_config.get("gitrepo_vector_search_index"),
text_column="text",
embedding=embeddings,
)
pdf_vector_search = DatabricksVectorSearch(
endpoint=model_config.get("vector_search_endpoint_name"),
index_name=model_config.get("pdf_vector_search_index"),
text_column="text",
embedding=embeddings,
)
# Create the retriever
gitrepo_retriever = gitrepo_vector_search.as_retriever(search_kwargs={"k": 4})
pdf_retriever = pdf_vector_search.as_retriever(search_kwargs={"k": 4})
# initialize the ensemble retriever to combine the two retrievers for aquiring different sources information based on the Reciprocal Rank Fusion algorithm.
ensemble_retriever = EnsembleRetriever(
retrievers=[gitrepo_retriever, pdf_retriever], weights=[0.5, 0.5]
)Creating RAG chain is straight forward unsing LangChain Chattemplate and format contents to pass them as a prompt.
# RAG Chain
# Method to format the docs returned by the retriever into the prompt (keep only the text from chunks)
def format_context(docs):
chunk_contents = [f"Passage: {d.page_content}\n" for d in docs]
return "".join(chunk_contents)
def extract_user_query_string(chat_messages_array):
return chat_messages_array[-1]["content"]
chain = (
{
"input": itemgetter("messages") | RunnableLambda(extract_user_query_string),
"context": itemgetter("messages") | RunnableLambda(extract_user_query_string) | ensemble_retriever | RunnableLambda(format_context),
}
| prompt
| model
| StrOutputParser()
)By using MLflow on Databricks, the chain content and prformance is trucked and useful to inspect the implementation. See exmaple below.
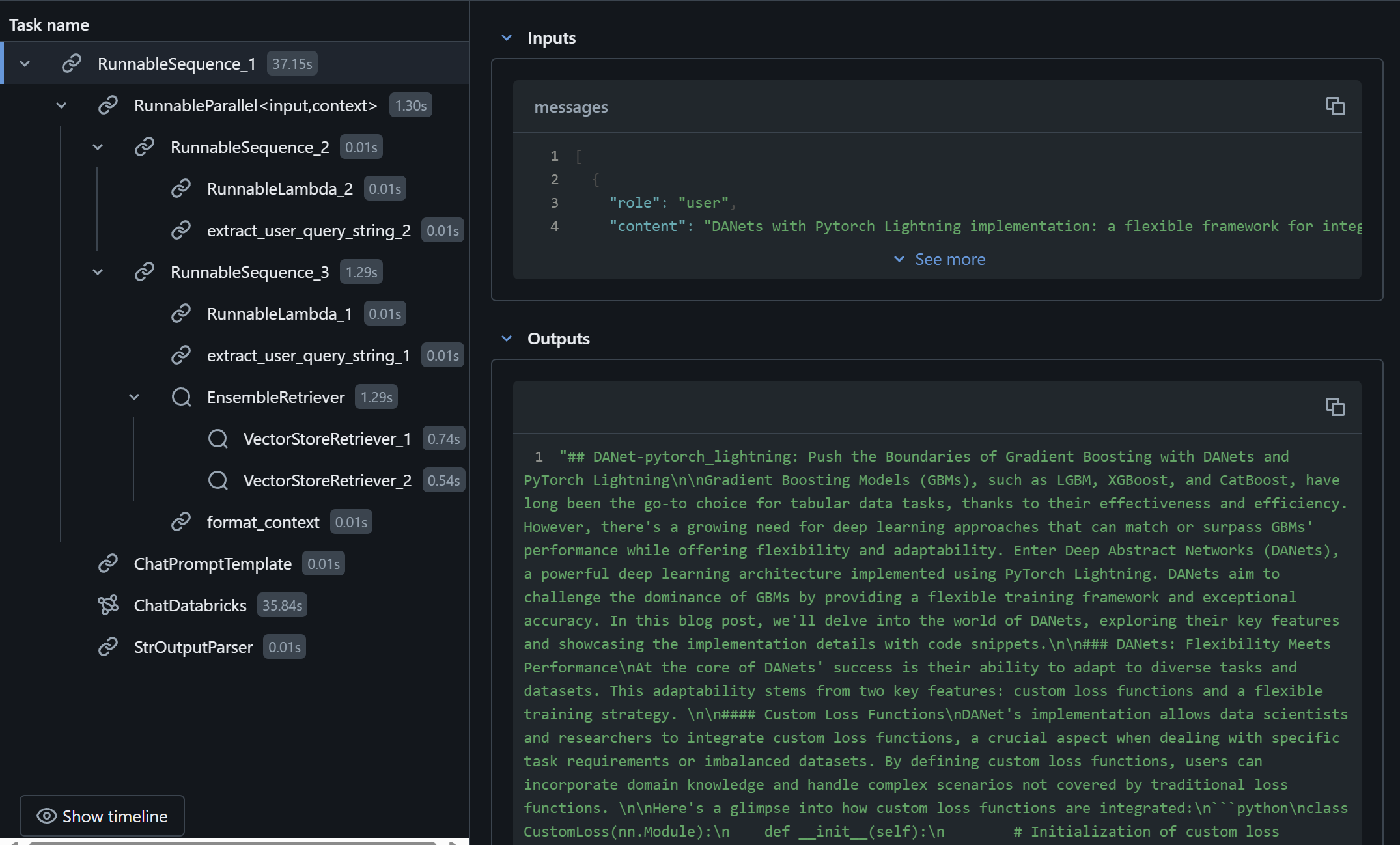
Deploying Agent Application to Host LLM Twin
Databricks offers hosting LLM as an agent on application. The chain is define in another code as python file (chain.py) and register model and chain by mlflow.langchain.log_model().
# Log the model to MLflow
with mlflow.start_run(run_name="twinllm_cohere_rag_bot"):
logged_chain_info = mlflow.langchain.log_model(
#Note: In classical ML, MLflow works by serializing the model object. In generative AI, chains often include Python packages that do not serialize. Here, we use MLflow's new code-based logging, where we saved our chain under the chain notebook and will use this code instead of trying to serialize the object.
lc_model=os.path.join(os.getcwd(), 'chain/chain.py'), # Chain code file e.g., /path/to/the/chain.py
model_config=chain_config, # Chain configuration
artifact_path="chain", # Required by MLflow, the chain's code/config are saved in this directory
input_example=input_example,
)
MODEL_NAME = "twinllm_cohere_rag"
MODEL_NAME_FQN = f"portfolio.twinllm.{MODEL_NAME}"
# Register to Unity Catalog
uc_registered_model_info = mlflow.register_model(model_uri=logged_chain_info.model_uri, name=MODEL_NAME_FQN)The registered chain can be deployed using library from databricks import agents. By accessing URL provided by the library and shown on the cell output, you can access agent application UI as shown in the sample video. This application can be used for multiple users and provide feedback on the text generated by LLM. The feedbacks can be then used to evaluate LLM accuracy from user experience and collected as data in delta table. The output of generated text can be amended by users and recorded to be used for further finetuning purpose.
Conclusion
Harnessing the power of Cohere and Databricks, you can now build end-to-end LLMOps with ease and deploy enterprise-level quality LLMs in just a day. Engineers can utilize these cutting-edge resources to significantly reduce time-consuming tasks, including personal branding efforts. Imagine having an LLM that assists with your daily tasks, freeing up your time for more strategic work.
Looking ahead, the concept of an LLM Twin could revolutionize the way we work, handling most of your tasks seamlessly. The future of AI-driven productivity is here, and it’s more accessible than ever. 🚀
DISCRAMER
This work is not affiliated with or endorsed by any parties. The author assumes no responsibility for the accuracy, completeness, or consequences of using the content provided. Use of the materials in this repository is at your own risk.
References & Links
Github repository for this work: takehiro177/LLMTwin-databricks-cohere
Linkedin profile: www.linkedin.com/in/takehiro-ohashi-b54101174
